
KumoRFM یک مدل پایه رابطهای مبتنی بر گراف ترنسفورمر است. این مدل ، به عنوان گامی مهم برای تحول در تحلیل پیش بینانه پایگاه دادههای ساختاریافته سازمانی مطرح شده است. با حذف نیاز به مهندسی ویژگی و ارائه پیش بینی صفر–شات، اکنون شرکتها میتوانند پیشبینیهای پیچیدهای مانند ریزش مشتری یا تشخیص تقلب را در همان لحظه و بدون تیم دادهکاوی انجام دهند.
چرا مدل پایه رابطهای (KumoRFM) مهم است؟
محدودیت مدلهای فعلی:
LLMs و روشهای RAG تنها روی دادههای متنی و موجود تمرکز دارند و قادر به پیشبینی وقایع آینده نیستند. در مقابل، شرکتها هنوز به روشهای سنتی ML برای مسائل مانند churn یا fraud متکیاند که زمانبر و پیچیدهاند .
حذف مهندسی ویژگی:
در روش کلاسیک، دادهها نیاز به «feature engineering» دارند که فرآیندی خستهکننده و زمانبر است. اما KumoRFM با تبدیل پایگاه داده رابطهای به گراف و اعمال یادگیری عمیق رابطهای، این گلوگاه را حذف میکند .
چگونه KumoRFM کار میکند؟
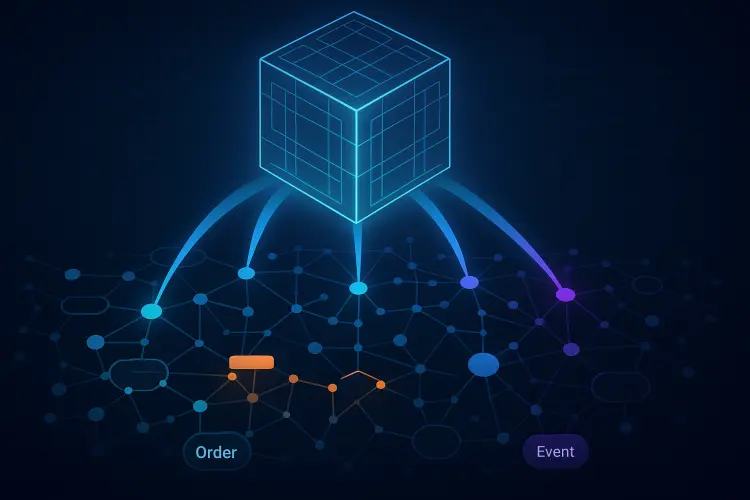
- نمایش پایگاه داده به شکل گراف:
جدولها و ردیفها به گره تبدیل شده و روابط foreign key به صورت یال تعریف میشوند. - گراف ترنسفورمر برای یادگیری:
مشابه LLM، اما توجه (attention) روی گراف اعمال میشود تا روابط پیچیده شناسایی شوند . - پیشبینی صفر–شات (Zero‑Shot) :
بدون نیاز به آموزش مجدد، KumoRFM با یک Query ساده به سرعت پیشبینی میکند،برای مثال احتمال سفارش مجدد مشتری در ۳۰ روز آینده .
")
مزایا و کاربردهای مدل پایه رابطهای
- سرعت بینظیر:
پیشبینیها کمتر از ۲۰۰ میلیثانیه انجام میشوند که سرعتی معادل هفتهها کار دادهکاوی است. - قابل استفاده توسط تحلیلگران:
رابط کاربری ساده برای تحلیلگران، بدون نیاز به تخصص ML . - پدیده «عاملمحور» آینده:
RFM میتواند موتور تصمیمگیرنده برای Agentهای هوشمند سازمانی شود؛ تصمیمات آن مبتنی بر دادههای سازمانی و قابل توضیح است.
ساختار معماری KumoRFM
زبان پیشبینی PQL:
مدل از زبانی شبیه SQL به نام Predictive Query Language برای تعریف مسئله پیشبینی استفاده میکند
اجزای کلیدی سیستم:
- تبدیل جدول به گراف چند زمانی با گرهها و یالها.
- رمزگذاری جدولعرضی invariant و توجه گرافی برای استخراج ویژگیها.
- یادگیری زمینهای بدون آموزش با استفاده از مثالهای گذشته.
- شرحپذیری (Explainability) : ارائه دلایل موثر در هر پیشبینی.
- امکان fine-tuning برای بهبود دقت روی دادههای خاص .
ارزیابی عملکرد KumoRFM
آزمایشها روی بنچمارک RelBench با ۳۰ وظیفه پیشبینی در هفت حوزه نشان دادند:
- پیشبینی in-context حدود ۲ تا ۸ درصد از روشهای متداول دقیقتر است.
- با fine‑tuning، بهبود تا ۱۰ تا ۳۰ درصد رخ میدهد.
- عملکرد بسیار سریعتر و بدون نیاز به feature engineering است .
چالشها و آینده راهبردی
- تنوع ساختار پایگاهها: توانایی OOTB در کار با شِماهای گوناگون یکی از نکات برجسته است.
- زیرساخت و منابع: پیادهسازی گراف ترنسفورمرها نیازمند GPU و پایگاه داده مقیاسپذیر است.
- مسائل حریم خصوصی و امنیت داده:
اما RFM میتواند درون سازمانی اجرا شود تا دادههای حساس خارج نشود.
نتیجه گیری
KumoRFM گامی تعیین کننده در جهت گسترش هوش مصنوعی به پایگاه دادههای رابطهای است. با حذف مهندسی ویژگی دستی و ارائه پیشبینی سریع، این مدل زمینه ساز نسل جدیدی از تحلیل پیشبینانه در سازمانها میشود.
- هماکنون نسخه دمو را امتحان کنید یا برای یک PoC داخلی برنامهریزی کنید.
- اگر دادهکاوی یا تحلیل پیشبینانه برای سازمان شما مهم است، بیدرنگ با Kumo وارد مذاکره شوید.


